
チャットGPTの世界的認知度の高まりとともに生成AIブームが起こり、株式市場にもその影響が波及してテクノロジー株が値上がりしてきました。
AIには機械学習用の高性能チップが欠かせません。そのため生成AIブームに乗っかり、半導体銘柄も値上がりしてきました。
AI向けチップと聞くと、9割の方はGPUを思い浮かべるのではないでしょうか。
機械学習には大量の学習データを高速で並行処理できる計算能力が必要で、それを最も得意とするのがGPUだからです。
こうした認識は世界の投資家も同じです。同じ半導体銘柄でも、GPU市場シェア8割のエヌビディアは年初来220%のリターンと群を抜いています。
でも、市場は機械学習にはトレーニング(学習)と推論という2つのプロセスがあることを忘れているようです。
大量のデータを学習するという、いわば「AIの脳をつくる」プロセスはトレーニングに該当します。これは機械学習のプロセスの一つに過ぎません。
もう一つの推論とは、トレーニングによって構築した「脳」を使って、新たなインプットに対して予測する(予測内容をアウトプットする)ことです。
いわば、大学で専門分野を学ぶことがトレーニングであり、そこで培った専門分野を実社会で活かしたり、実社会での経験を通じてより洗練された仕事をすることが推論にあたります。
大学での学習期間は一般的に4年間ですが、社会人になって実社会で働く期間は40年以上あります。
AIでも似たようなものです。最初に集中的にトレーニングした後は、推論での使用がメインになり、その期間はトレーニング期間の何倍にもわたります。
長期的には推論の方がトレーニングよりも処理回数は圧倒的に多くなりますし、消費電力も増えていきます。長期的に推論は機械学習コストの大半を占めることは確実で、最大9割を占めるとの推定もあります。
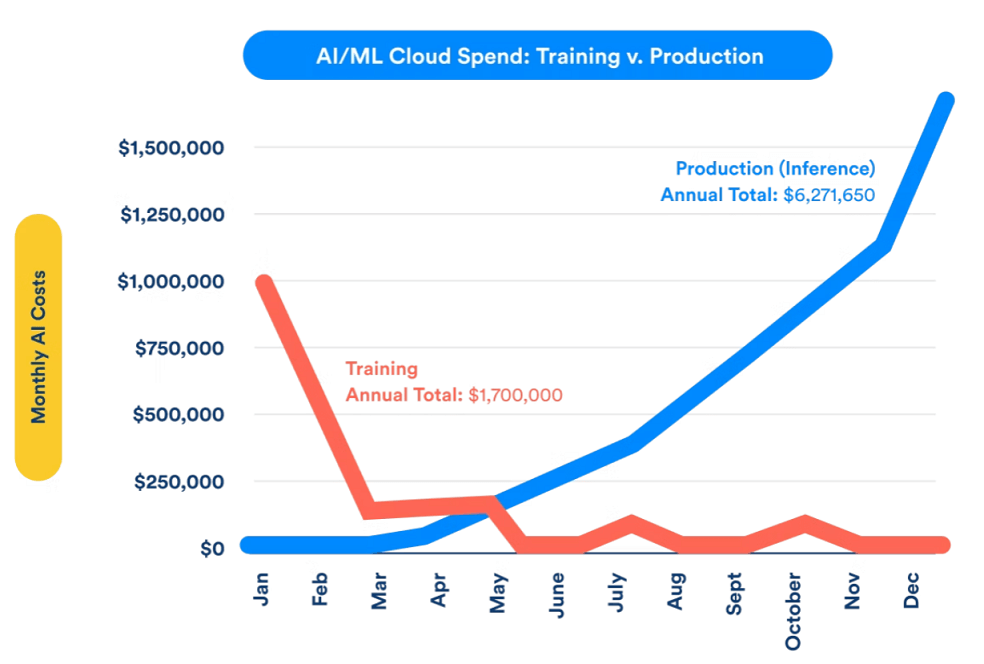
推論ではトレーニングほど高い精度は求められませんが、代わりに実行時間の短さが求められます。
チャットGPUを利用された方は質問を出してから回答が出るまで数十秒~1分程度掛かり「長いな…」と思われたことでしょう。これが数秒で回答が出れば便利だと思いませんか?
推論の実行時間のボトルネックとなっているのが、CPU-GPU間のデータ転送の遅さです。
もし推論をGPUで行うとなると、CPU側のメモリからGPU側のメモリにデータを渡し、処理した結果をCPU側のメモリに転送するというプロセスが必ず発生します。
計算は必ず、オペレーティングシステム(WindowsやMac OSなど)の動いているCPUから始まるためです。
たしかに計算能力の高いGPUはCPUよりも推論時間は数分の1以下で済みます。しかしCPUのデータをGPUに転送するスピードは、CPUの中でデータを複製する場合より6~7倍も遅いとされます。
推論ではCPUの高速化も必要ですし、CPUとメモリやGPUなどとのスムーズな連携が欠かせません。そのためには高度なパッケージング技術が必要になってきます。
単純にGPUを10倍、100倍に高速化してもボトルネックが解消するわけではないのです。
★本日はアボマガ・エッセンシャルの配信日です。
機械学習の中心はトレーニングではなく推論である点に着目すると、将来勝者になれるチップ会社も変わってきます。
市場が「機械学習=トレーニング=GPU」という固定観念に縛られているあいだに、将来勝ち組になりそうな割安チップ企業に投資して100%、200%、500%のリターンを掴みにいきませんか、という話です。